
In a series of four, Senior Project Manager and 7N IT specialist, Lars Søndergaard, focuses attention on what challenges and possibilities he sees with data migration in the pharma industry. Besides management,
Lars possesses data warehouse and business intelligence as core competencies and has more than 20 years of experience within his field. He has gained a lot of his experience within the pharma industry, the latest from an assignment at LEO Pharma as a Project Manager and Data Governance Consultant.
Agile data migrations
Most projects nowadays are using agile principles, maybe in a scaled framework or maybe in core agile.
In all cases, DoD, DoR, refinement process, and team organization should be designed considering both Configuration and Data migration.
In theory, the refinement for a given sprint should describe all business rules required for the scrum team to deliver all technical functionalities related to a given user story in scope for the sprint.
The configuration effort for a given Use Case can be large, small, or even nonexistent if the standard functionality can be used directly.
One User story can consume data from a multitude of data objects making the data migration effort too large for the team to deliver in one sprint.
In the case of multiple feature teams, the development of data migration functionality for one specific Data Object would be split into several feature teams, increasing the need for cross-feature team coordination, and maybe even more severe, that data migration resource requirements would exceed available resources.
Due to the cross-functional nature of data and the specific technical platform required to deliver the data migration, the data migration development should be organized as a component team (in SAFE terms).
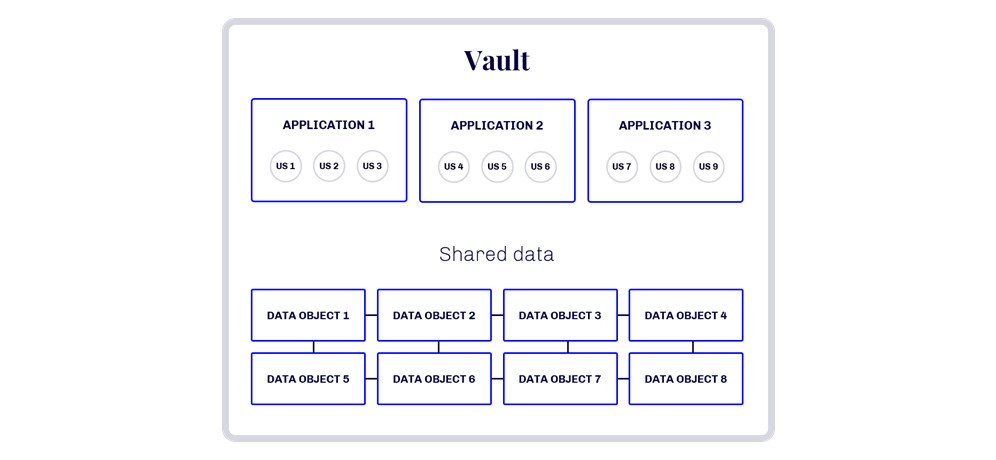
However, the data migration team needs to coordinate closely with the feature teams:
- Participate in shared refinement sessions between Feature and Data migration teams to clarify data requirements and potential impediments stemming from source data quality issues.
- Participate in overall sprint / PI planning to coordinate sprint objectives.
- Veeva solution architect tasks should include support to the Data migration team (questions, configuration refreshes, etc.)
If the project uses SAFE, the Feature DoD should address the required data for a feature to be ready for release.
Hereby, a coherent set of user stories are demonstrated with data, ensuring that the new solution works as intended. If that is not the case, there is enough time to mend any configuration or data migration shortcomings.
If the project uses core agile, major sprint reviews can be planned where user stories and data can be demonstrated together.
It is not advised to pursue a strategy where the configured solution and migrated production data are tested for the first time via, e.g., a user acceptance test before the final validation.
- The risk of finding severe defects very late in the project would be too high. It could probably lead to delays in project delivery.
The data migration product backlog
The data migration product backlog should be organized according to Veeva data objects.
It could be argued that all source data needs to be migrated. Hence, it should be the source data that should constitute the product backlog for the data migration product backlog.
But not all physical source data are required to be migrated when establishing a new system.
Some physical data are redundantly stored. Some data are not in scope for the new business processes. Some physical tables are not used at all.
In reality, the new business processes and the data consumed here drive the data migration requirements, making the target data object the best product backlog item.
Using the Veeva data object model to organize the product backlog gives the project a catalog of product backlog items via the Veeva configuration file.
Veeva includes a business label for all objects, making it easy to discuss with businesses what data objects are in scope.
Definition of Done
DoD should be focused on that the Production data are migrated all the way to the Veeva vault.
In other words, within a sprint, the data migration team should be able to develop the following:
- Source data extracts
- Data curations
- Data transformations
- Dispatching of data to the Veeva vault
Using production data is utterly essential to identify critical data quality challenges as early as possible. Using production data in the sprints is the only way to truly know if a product backlog item is done-done.
It should be considered to extend the standard acceptance criteria such as "no critical defects", with measures for how significant a percentage of the source data is successfully migrated before being done in a sprint and a release.
If the production data in scope is GDPR compliant or business-critical, required IT security policies must be followed. Cumbersome, but worth the effort.
Overall sprint planning
When using the data objects to structure the product backlog - One target data object equals one product backlog item - it is crucial to understand:
-
The internal constraints between data objects:
- In the Veeva Data Object Model, you will find relational-like limitations. For instance, the data object Study-site needs a Study and a site data object before it can be created.
- Other process-oriented constraints are typically implemented in the configuration process.
- In the Veeva Data Object Model, you will find relational-like limitations. For instance, the data object Study-site needs a Study and a site data object before it can be created.
-
Which user stories consume data from which data objects:
When making the overall sprint plan, it is important to take these considerations into account.
The overall sprint plan should focus on a meaningful implementation order of user stories. Still, from a data migration perspective, it is necessary to understand and be able to identify:-
- If a data object needs to be implemented in different versions, supporting different user stories in different increments/sprints.
- Complexities regarding muck-up data for parent data objects if parent data objects are implemented later.
- If a data object needs to be implemented in different versions, supporting different user stories in different increments/sprints.
If meaningful, the overall sprint planning should minimize this overhead.
As a minimum, the product backlog should reflect the above. Otherwise, the data migration product backlog would not be complete, and the effort required to deliver a specific product backlog item would be underestimated.It is not a small task to gain the required insight into data object constraints and map user stories and data objects down to the attribute level.
The overall sprint planning process should allow time for the analysis and collaboration between the data migration team, LoB SME's, and Veeva configuration leads in order to gain enough insight to deliver a robust overall sprint plan. -
Interested in more?
Read the other parts of this article by following the links!








